System Design - Google Drive Like
System Design Exercise #2
Concevoir un “Google Drive” simplifié : pourquoi ton backend ne doit jamais transporter les bytes
Énoncé
On veut un service de stockage et de partage de fichiers “type Drive”, en version volontairement réduite :
- Upload de fichiers (jusqu’à 5 GB).
- Download rapide (latence faible).
- Suppression.
- Partage via lien public.
- Versioning simple.
- Synchronisation multi-devices (cohérence “raisonnable”, pas forcément forte partout).
- Échelle : 50M users, 10M DAU, disponibilité élevée.
C’est le genre de sujet qui piège vite : tu peux partir sur une implémentation “logique” (backend reçoit des chunks, reconstitue, stocke) et te retrouver à inventer un système de streaming distribué à la main, avec des websockets, des threads, des transactions impossibles, et des problèmes de reprise en cas de crash.
Le but de cet article : dérouler le raisonnement qui mène à une architecture saine, scalable, et défendable en entretien.
Problématique réelle
Ce système a deux natures très différentes :
- Transport et stockage de gros volumes de bytes (fichiers de plusieurs GB, beaucoup d’utilisateurs en parallèle).
- Gestion de vérité métier (qui possède quoi, quelles versions, quel état, quels liens publics, quelles règles d’accès).
Si tu mélanges (1) et (2) dans la même brique (ton backend), tu te crées un goulot d’étranglement, puis tu passes ton temps à colmater :
- threads par upload,
- sticky sessions sur le load balancer,
- RAM/CPU qui explosent,
- reprise impossible sans ré-uploader,
- et une fausse idée de “transaction” qui englobe S3 + Postgres (ça n’existe pas).
Donc, dès le départ, tu dois séparer :
- Control plane : orchestration, sessions, permissions, metadata.
- Data plane : transfert des bytes, stockage objet, distribution.
C’est le pivot du design.
Invariants à fixer avant de dessiner quoi que ce soit
Invariant 1 — Un fichier n’est lisible qu’après commit
Tant que l’upload n’est pas terminé, l’objet est “fantôme” :
- visible en UI éventuellement (grisé / pending),
- mais pas téléchargeable.
Donc il existe un état : PENDING => COMMITTED (et éventuellement ABORTED).
Invariant 2 — L’atomicité se fait côté metadata, pas côté bytes
On ne peut pas faire une transaction Postgres + S3. Le seul endroit où tu peux garantir “visible vs invisible” de manière atomique, c’est ta base de données.
Donc :
- les bytes peuvent exister avant,
- mais la version n’est “réelle” qu’à partir du commit DB.
Invariant 3 — Le backend ne doit pas streamer les bytes
Tu peux l’autoriser dans une version prototype. Pas dans un design “50M users”. Le backend doit rester un orchestrateur, pas un tuyau.
Pourquoi “WebSocket + backend qui recompose” est le mauvais axe
C’est tentant : tu fais du chunk upload, tu ouvres une WS, tu envoies un % de progression, tu reconstitues le fichier, puis tu pushes sur S3. Sur le papier : ça marche.
En pratique, tu te heurtes à des problèmes structurels :
1) L’état d’upload ne peut pas vivre en RAM
Le jour où une instance redémarre, tu perds :
- quels chunks étaient reçus,
- où tu en étais,
- et tu ne peux plus reprendre “à 90%”.
Tu vas alors inventer un état persistant… donc tu finis par recréer un système qui ressemble à un multipart upload, mais en pire.
2) Les threads ne “scalent” pas comme tu l’imagines
10k clients qui uploadent en parallèle => tu n’as pas “10k threads”. Tu as :
- du scheduling,
- de la contention,
- de la mémoire par connexion,
- des buffers réseau,
- des GC pauses,
- et des timeouts.
Tu te retrouves à faire de la gestion de backpressure à la main, au niveau process + cluster, juste pour transporter des bytes que d’autres systèmes savent déjà transporter.
3) WS pour download t’empêche d’utiliser les standards
Le download “bien fait” utilise :
- HTTP GET,
- Range requests (reprise, streaming),
- CDN (cache, proximité, débit),
- retries automatiques clients.
WS te sort de cette autoroute et te met sur une départementale.
Le raisonnement qui mène à “multipart upload + URLs signées”
Si ton backend ne doit pas transporter les bytes, alors il faut que le client parle directement au stockage objet.
Problème : tu ne veux pas donner tes credentials S3 au client.
Solution standard : URL signée (“presigned URL”).
URL signée : définition opérationnelle
C’est une URL vers S3 (ou GCS) qui inclut :
- une signature cryptographique,
- une expiration,
- et une permission implicite (“tu as le droit de PUT ici pendant 15 minutes”).
Le client peut donc uploader un chunk directement sur S3, sans être “AWS-authentifié” de manière générale.
Multipart upload : définition opérationnelle
Au lieu d’envoyer un fichier monolithique (5GB), tu crées un upload multipart :
- le stockage accepte des “parts” numérotées :
partNumber = 1..N, - chaque part est uploadée indépendamment,
- puis tu demandes au stockage d’assembler toutes les parts en un objet final.
Ce mécanisme règle trois problèmes d’un coup :
- gros fichiers (chunking),
- reprise (il manque seulement certaines parts),
- idempotence (ré-uploader la part 7 ne casse pas l’upload).
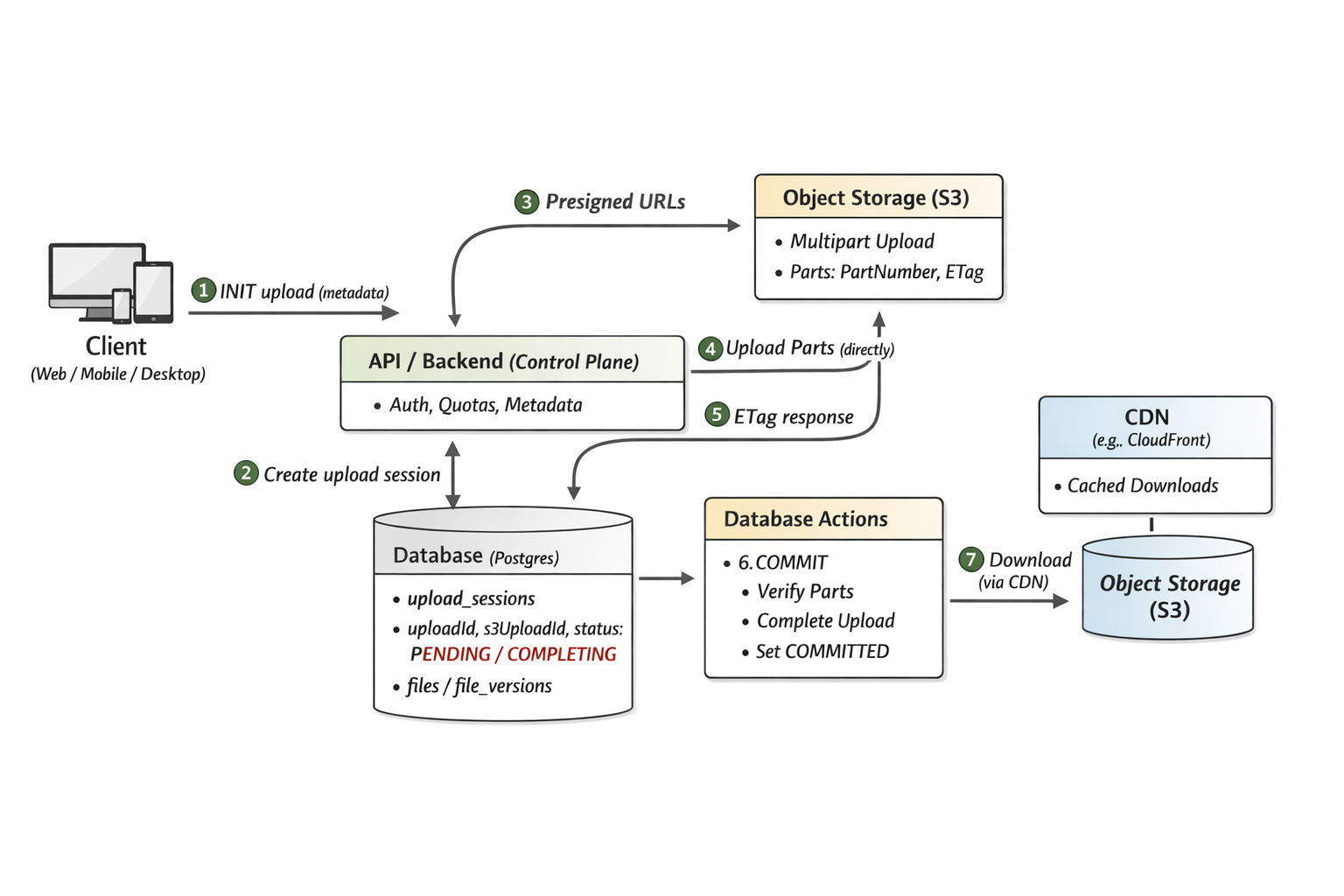
Architecture cible (control plane vs data plane)
Briques
API / Backend (Control Plane)
- AuthN/AuthZ
- quotas
- création de sessions d’upload
- génération d’URLs signées
- commit
- metadata (files, versions, share links)
Object Storage (Data Plane)
- bytes
- multipart upload
- durabilité
CDN (Data Plane, pour download)
- cache
- proximité géographique
- débit
DB (source of truth)
files,file_versions,upload_sessions,share_links
Le flux upload, étape par étape (vraiment)
1) INIT : créer une session
Le client appelle le backend avec :
- filename
- size
- mimeType
- parentFolderId (si tu gères les dossiers)
- checksum global (optionnel au début)
Le backend :
- vérifie auth + quotas
- calcule
partSize(ex : 8MB, 16MB) - calcule
expectedParts = ceil(size / partSize) -
crée
upload_sessionen DB :uploadId(ton UUID)status = PENDINGexpectedPartspartSize
- crée un multipart upload côté storage (retourne
s3UploadId) - génère des URLs signées (au minimum “à la demande” ou par batch)
Le backend renvoie :
uploadIdpartSize- un lot d’URLs signées :
(partNumber => url)(ou un endpoint pour les demander page par page)
2) Upload des parts (direct vers S3)
Le client coupe le fichier en parts via streaming (pas 5GB en RAM) :
- navigateur :
file.slice(offset, offset+partSize) - desktop : stream file + chunking
- mobile : stream file + chunking
Chaque part est envoyée à S3 via PUT presigned-url.
Réponse S3 : 200 OK + ETag.
Le client conserve la liste :
(partNumber, etag)pour toutes les parts uploadées.
Progression upload Pas besoin de websocket :
progress = uploadedParts / expectedParts- tu as un % fiable, basé sur ce que tu as réellement réussi à envoyer.
3) COMMIT : finaliser
Le client appelle le backend :
uploadId- la liste
(partNumber, etag)
Le backend fait trois actions, dans un ordre important.
a) Verrou logique (anti double-commit)
Tu veux éviter deux commits concurrents.
Tu fais un compare-and-set :
- passe
upload_session.statusdePENDINGàCOMPLETINGsi et seulement si il est encorePENDING.
Si ça ne passe pas, tu renvoies :
- soit
409 Conflict(commit déjà fait) - soit
200avec l’état final si tu veux être nice.
b) Compléter le multipart upload côté storage
Le backend appelle S3 : “complete multipart upload” avec la liste des parts. S3 assemble, et l’objet final existe maintenant.
c) Transaction DB : rendre visible
Seulement maintenant, tu commits la vérité métier :
- créer
file_versionavecstorageKey,size,checksum,createdBy, etc. - passer la version à
COMMITTED - marquer la session
COMMITTED
À partir de là, le fichier est lisible.
4) Échec et nettoyage (inévitable, donc prévu)
Deux types d’orphelins possibles :
-
Bytes sans metadata : S3 a reçu des parts ou même un objet final, mais la DB commit a échoué.
- solution : TTL sur sessions + job de garbage collection, ou “abort multipart upload” sur expiration.
-
Metadata sans bytes : tu l’empêches par design (tu ne commits DB que si S3 completion a réussi).
Download : CDN + HTTP Range, pas “chunks via backend”
Pourquoi
Le download doit être rapide, massif, et bon marché à servir. Ton backend n’est pas un serveur de fichiers à l’échelle mondiale.
Comment
- Client appelle :
GET /files/{fileId}/download -
Backend vérifie permissions, puis renvoie :
- une URL signée de download (ou une URL CDN protégée)
- Client télécharge via HTTP standard.
HTTP Range permet :
- reprise après coupure,
- streaming,
- téléchargement partiel.
Le CDN ajoute :
- cache,
- proximité,
- débit,
- réduction des coûts de sortie et de charge sur S3.
Suppression : “immédiate” côté metadata, async côté bytes
Ici aussi : deux plans.
-
Immédiat : rendre le fichier inaccessible.
- tu mets
deletedAtoustate=DELETEDdans la DB. - les liens publics deviennent invalides (ou renvoient 404/410).
- tu mets
-
Asynchrone : nettoyage des bytes.
- job qui supprime les objets S3, ou lifecycle rules.
Sémantique propre :
- pour l’utilisateur, c’est supprimé immédiatement,
- pour l’infra, c’est nettoyé de façon fiable.
Partage via lien public : token => file/version
Dans ce scope “simplifié”, pas de partage de dossiers ni d’écriture par le lien.
Tu stockes :
share_links(token, fileId, versionId?, expiresAt, revokedAt, permissions=read)
Accès :
GET /s/{token}=> vérifie expiration / révocation => renvoie URL de download signée.
Ça évite de faire un ACL engine complet.
Versioning simple : append-only sur les versions
Un piège courant : “je remplace le même objet S3”.
Pour le versioning, le modèle stable :
- chaque version écrit un nouvel objet immuable (nouveau
storageKey) file_versionsest append-only
Tu peux ensuite décider d’une politique :
- conserver N versions,
- ou conserver T jours,
- ou conserver selon quota.
GC = supprime les vieux storageKey.
Sync multi-devices : ne pas modéliser Device×File
Le réflexe “table Device + relation Device<->File” explose en cardinalité. Un sync scalable se base sur :
- un journal de changements (append-only) ou un curseur.
Idée minimale :
- tu stockes pour chaque user un flux de changements : “file X version Y committed”, “file X deleted”, etc.
- chaque device garde un
cursor(last seen event id) - il demande “donne-moi les événements depuis cursor”
C’est cohérent avec “cohérence raisonnable” :
- tu acceptes un léger retard,
- tu as un mécanisme simple, scalable.
Ce que tu peux défendre en entretien
Les phrases clés
- “Je sépare control plane et data plane.”
- “Le backend ne transporte pas les bytes : il orchestre.”
- “L’atomicité est une transition d’état en DB (PENDING => COMMITTED).”
- “Les gros fichiers se gèrent via multipart upload et URL signée.”
- “Le download passe par CDN + HTTP Range.”
Les trade-offs assumés
- “Le partage est via lien public read-only, pas d’ACL ni dossiers partagés.”
- “La suppression des bytes est async, mais la suppression logique est immédiate.”
- “Le versioning est append-only, avec GC.”
Conclusion
Le point central n’est pas “comment je découpe un fichier en chunks”. Ça, tout le monde sait le dire.
Le point central est : où passent les bytes, et où se fait la vérité.
Dès que tu décides que :
- les bytes vont directement vers object storage,
- et que la DB décide du moment où un fichier devient “réel”,
tout le reste devient mécaniquement plus simple :
- reprise,
- retries,
- scalabilité,
- coût,
- cohérence.
Et tu ne te retrouves pas à coder un mini-S3 dans ton backend.